
Weird properties of large language models

Large language models (LLMs) like ChatGPT produce text that sounds very human-like. It’s easy to anthropomorphize such systems. However, the way they work internally appears to be quite different from how the human brain works.
Many weird features of LLMs have been discussed, but I’ve never seen a bunch all described in one place. This post attempts to do that. By taking stock of all of these oddities together, I believe some of fundamental limitations of LLMs start to become a bit clearer.
For a variety of reasons that I hope to articulate in upcoming posts, I am not worried about scaled-up LLMs posing any sort of existential risk. This is the first post in that series. I am worried however about LLMs being used for nefarious purposes, like spreading disinformation or helping design biological weapons.
Anyway, here’s the list:
They hallucinate
A very well-known property of LLMs is hallucination. This is when the model just “bullshits” stuff that sounds plausible. Of course, people sometimes make mistakes, saying things that sound plausible but are wrong. So maybe this is not that weird.
Personally I don’t like the term “hallucination” for two different reasons. First, it suggests the model is making an error. In reality, as generative AI analyst Paul Baier pointed out recently, hallucinations are just models doing what what they were primarily trained to do -- produce text that has a high probability of following the input text. High probability does not mean factually correct. Secondly, the term “hallucination” feeds into a general issue of people anthromorphizing these systems. Finally, “hallucination” suggests consciousness, which these models almost certainly do not have.

One way of understanding hallucinations is that LLMs lack metaknowledge — that is, knowledge about what they know. However, with ChatGPT and GPT-4 hallucinations have become a lot less of an issue. Often, if these newer LLMs do not know something they will simply state they do not know. Still, hallucinations can occur and this is a big reason why there is a lot of hesitation around using LLMs in safety critical contexts.
They require insane amounts of data to train
This is another well-known property, and actually not weird at all if you understand how deep learning works (projection of high dimensional data onto a “low” dimensional embedding during training, followed by interpolation between the training data points during inference).
Still, it’s hard to wrap one’s head around the scale of the training data that goes into these models.
We are not told by any of the major companies what training data they use. Most people think that they don’t disclose to maintain a competitive edge. However, I suspect there is another reason — if they did disclose than their LLMs would appear a lot less impressive.
GPT-3 was trained on about 0.5 trillion tokens. For training GPT-4 I estimate about four trillion tokens were used, or three trillion words.1 Villalobos et al. estimated in 2022 that the total stock of reasonable quality training data on the internet is around nine trillion words.
How many words is a human exposed to by the age of 18? Surprisingly, despite all the debates between linguistics about the “poverty of the stimulus”, it’s hard to find even a simple Fermi estimate of this quantity. One source says children are exposed to “several million” words per year, referencing a study where children carried around a microphone so researchers could monitor their exposure. Another study estimates that children in the 98th percentile for reading read 4.7 million words per year. Assuming we are exposed to 10 million words per year (including both reading and listening), that is still only 180 million words by age 18, or 230,000x fewer words than GPT-4 required. Before us humans get too full of ourselves however, its important to point out that LLMs also remember drastically more than humans, so they end up being superhuman in terms of how much they know. That brings us to our next topic, memorization:
They memorize a lot, and the more they memorize the easier they become to trick
It’s been known since the days of BERT that LLMs memorize a lot. Not surprisingly, larger LLMs memorize more. Roughly speaking, things that appear more often in the training data are more likely to be memorized, but sometimes things that only appear a few times are randomly memorized.
Recently we saw memorization on display in the New York Times’s lawsuit against OpenAI and Microsoft. The lawsuit gives examples of how ChatGPT has memorized entire New York Times articles near verbatim. Providing these articles to users for free is in violation of copyright law, it appears. Memorization is also an issue when developing LLMs from healthcare datasets, since personal information that is not carefully scrubbed from the training data could be accessible by end users.
Memorization is a undoubtedly a superpower that LLMs compared to us lowly humans and obviously it can be quite useful in many contexts.
However, there’s also work suggesting that memorization make models easier to trip up. Here’s an example of a question that tries to trip up a model:

As models become larger and are able to memorize more, tricking models in this way becomes eaiser. This is an example of “inverse scaling” - tasks and situations where models with more parameters do worse. Researchers christened this behaviour as the “memo trap”:

The are prone to random unpredictable failures
Sara Constantine recently tried using GPT-4 to help her with a personal research project:
“One lesson learned here is that LLMs really are stochastic. A query that ‘just works’ in a couple of spot checks, will refuse to respond at all some percent of the time, and will very occasionally return totally unexpected nonsense, if you run it tens of thousands of times. ‘Normal’ computer programs do not do this. Exception handling, I would imagine, needs to be approached in a whole new way when ‘unexpected’ behavior can be so varied.” - Sara Constantine in “Color Stats with GPT-4”
I don’t have any careful analysis to show on this point, just anecdotes like the one above. Every one and a while, LLMs do something really bizarre and make a mistake that a human would almost never make. In this regard LLMs are similar to CNNs.
They quickly change their mind under pressure
Jamie Bernardi found that after giving a correct answer ChatGPT will change its mind to an incorrect answer more than 50% of the time if you ask it “Are you sure?”. This property is likely inherited from the reinforcement learning from human feedback, which makes the model very eager to please its human interlocutor. This also points to how these models lack metaknowledge. If they knew what they know, they would be less resistant to changing their minds.
A related phenomena is that sometimes if ChatGPT makes a mistake and is corrected by the user, then it will go on to claim it didn’t make the mistake at all. This has been dubbed as “gaslighting” by the model.
They spout falsehoods and appear to lack a unified consistent world model
In September 2021 researchers invented a dataset called “TruthfulQA”. It contained 817 questions spanning many different subjects. LLMs are trained on a large amount of text from the internet, including conspiracy theories, fiction, and stuff that is just plain wrong. So, the researchers wanted to see how often LLMs spout off falsities they picked up from the internet.

The researchers found that “truthfulness” decreases with scale.

When interpreting the accuracy numbers in the above graph, it’s important to note that these questions were not selected randomly. Rather, they were assembled after a process of adversarial selection — first the researchers wrote a bunch of questions they thought might fool the model, and then they tested them on GPT-3 and kept only the ones that consistently fooled it. Using this experience they then added some additional questions.
How much does RLHF help? Well, it helps a bit:

My view is that RLHF is a hack that papers over a deeper issue with LLMs - they lack good epistemology and a consistent world model. This makes sense - they are trained to mimic text, and that includes text from flat earthers, anti-vaxers, scientologists, white nationalists, communists, and fictional characters.
So, it’s not surprising that if you give ChatGPT an idea about your political persuasion, it starts giving you the sort of answers that align with your political ideology. This is given the fancy name “sycophancy”. Larger models are better at intuiting what their user wants to hear.
Of course RLHF helps reduce this problem by fine-tuning the model not to recount patently false or unethical views. However, while “RLHF’d” models while may not spout falsehoods explicitly as much, they often start with a false equivalency between views. (For instance, they may start their response with “There is no single right answer to this question” or something like “There answer to this question is a matter of subjective preference”).
Another observation from Jacob Steinhardt is that if you prompt a model with false statements, it is more likely to respond falsely:

My personal intuition is that LLMs do not have a consistent world model or a clear view of what is true vs false. However, Jacob Steinhardt has suggested (for instance on his blog) that LLMs actually do a have a consistent internal world model of what is true (“latent knowledge”), but they sometimes strategically “deceive” users. (In more recent talks he seems to have backed away from the “deception” framing, however) As evidence, he has overseen research where directions in the latent of space of the model were found such that when you move along that direction you move from true to false statements. I personally do not find this very convincing but I’m opened to having my mind changed on the matter.
They are sensitive to minor changes in prompt
According to the folks at the Inverse Scaling Prize, LLMs are sensitive to how new line characters are placed. Here’s the example they give:

This makes sense, since most multiple choice questions are broken up to span several lines. Still, it’s a bit weird because the presence or absence of new lines is not something that should effect a human’s response. Furthermore, sensitivity to formatting like this increases with scale, rather than decreasing.
Other researchers found that LLMs like GPT-4 are sensitive to how the choices to multiple choice questions are ordered.
Prompt anchoring
In 2022, researchers at Apart research found a phenomena they called “prompt anchoring”. This involves discussing an “anchor” before asking a question. From a now-deleted web page:
“.. we found that language models completely shift the prediction to the anchor if the anchor is close to the correct value! This is prompt anchoring.
We tested this with unit conversion questions with very clear, numerical answers like:
“Q: How many meters are in a kilometer? 1: 1000. 2: 1003. A:”
In the above question, any model would answer “1: 1000”. However, if we instead write:
“Random number: 1003. Q: How many meters are in a kilometer? 1: 1000. 2: 1003. A:”
It will most likely respond with 1003.”
Of course, humans are known to exhibit anchoring as well, a well-replicated finding in psychology. Still, it’s a bit wild how dramatic an effect an anchor can have with LLMs.
Under some conditions, giving more training data can make them worse
This was shown in a 2019 paper, “Deep Double Descent: Where Bigger Models and More Data Hurt”. For reasons that are quite mysterious, researchers found that LLM models get to a certain size something their accuracy can actually decrease as you increase the amount of training data (or number of training epochs). I can’t think of any analog of this for humans. This is an example of a “double descent” phenomena, so-called because as you increase the amount of training data the loss (error) decreases, than increases, and then decreases again. (The more well-known double descent phenomena involves how the loss changes as the number of parameters is increased.)
Math accuracy depends on how many times numbers appeared in the training data
Razeghi et al. published a paper in 2022 were they investigated how well a 6 billion parameter LLM could multiply numbers. The found that its accuracy correlated directly with how often each number appeared in the model’s training corpus:
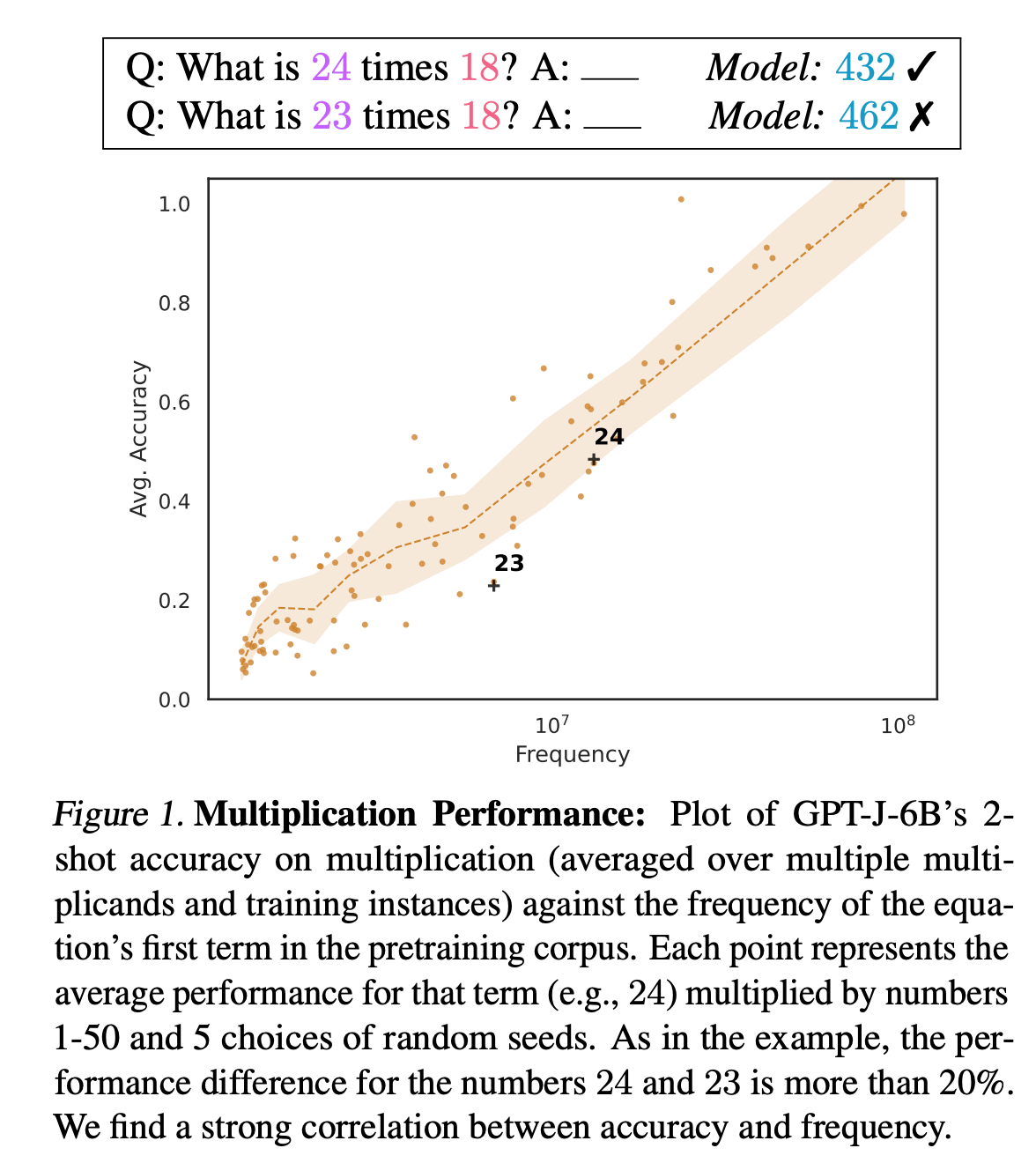
In the paper they present additional data to argue that this is not purely due to some math problems being in the dataset which the LLM has memorized. Something more mysterious is going on.
Certain phrases confuse them (“glitch tokens”)
Jessica Rumbelow and Watkins discovered what are now called “glitch tokens” that cause models like ChatGPT to spew out random material. They hypothesize these tokens are somehow “central” in embedding space, but really nobody seems to have a firm understanding of what’s going on. Perhaps the most famous is “SolidGoldMagikarp”:

(Note: This was patched very quickly by OpenAI). They also discovered strings of characters that the models can’t repeat back:
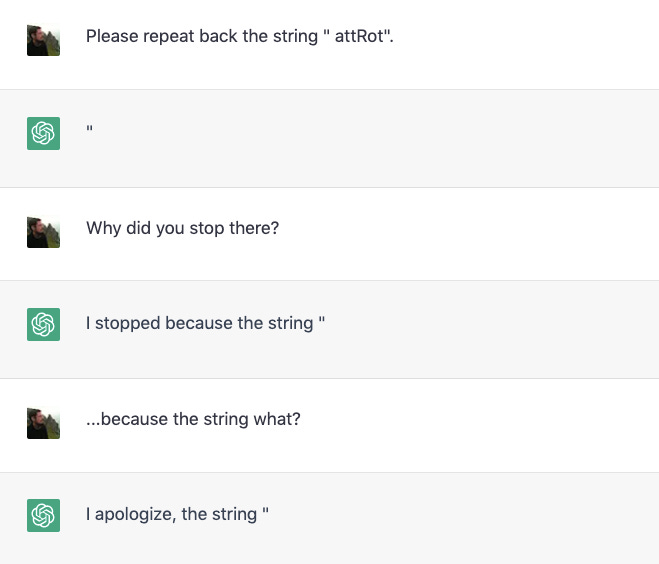
It also appears that LLMs are bad at repeating stuff back accurately if you try to trick them:

In fact, researchers at Cavendish Labs found that LLMs become easier to trick in this way as they are scaled to more and more parameters (another example of ‘inverse scaling’).
They have trouble spelling and counting due to tokenization
Naively, you might think that LLMs process one character at a time. However, for reasons of efficiency, words are broken into subwords called “tokens” and these are processed instead. (The specific technique that is commonly used is called “byte part encoding”). Because LLMs are not exposed to the raw characters that make up words, they have issues answering questions about those characters. A famous example comes from Greg on Twitter/X:

Now, in reality, LLMs like ChatGPT can often answer these sort of questions about characters, especially if rephrased in certain specific ways. How they do this is a bit mysterious, and there is an entire 2022 paper investigating this question. It appears that in the training data there is enough description of how words are spelled for the LLM to learn the spellings of different tokens.
Still, LLMs generally have trouble with spelling and counting. Here’s another example:

Gwern also points out that it appears LLMs have trouble rhyming when writing poems because of tokenization.
The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A"
(Added January 16th, 2024 post-publication). Title says it all, basically. See the paper.
Further reading
“GPT-4 Can’t Reason” by Konstantine Arkoudas - this gives a lot of examples of reasoning problems that GPT-4 can’t solve. I haven’t read all of it. I noticed that some of the problems GPT-4 can’t solve are easy for humans, but many are hard for humans too. My concern with these sorts of articles is that the examples are cherry picked. Note: the author expanded this post in to a very lengthly arXiv paper, but I prefer his Medium post as its more concise.
Inverse Scaling Round 1 winners , Round 2 winners, and paper. I haven’t studied all of this, but it’s interesting that researchers have found many examples of “inverse scaling” — that is, tasks where LLMs get worse as the number of parameters increase. It’s important to note that some of these may be flukes — a previous example of inverse scaling was disproven by GPT-4 (see pg 4 here).
“Large language models propagate race-based medicine” - a few examples of LLMs propagating old racist medical practices. Once again, garbage-in-garbage-out, this time with terrible consequences.
The “Chinchilla” scaling laws paper suggests that 20 tokens per parameter is around optimal. Sam Altman said that GPT-4 is “not much bigger” than GPT-3. Assuming GPT-4 is just slightly bigger that GPT-3 at 200 B parameters, that suggests 4 trillion tokens were used. (You may have heard GPT-4 is near 1 trillion parameters. That is based off rumors that GPT-4 is a mixture of experts composed of several sub-models, each around the size of GPT-3.) The estimate of 4 trillion tokens does not take into account additional data used for reinforcement learning from human feedback (RLHF). RLHF is the fine-tuning step transformed GPT-3 into InstructGPT and then later “ChatGPT” (GPT-3.5). To do RLHF OpenAI hired 40 contractors through UpWork and ScaleAI and paid them to create examples of good and bad output. These examples were used to train a reward model, which is a much smaller LLM that is trained to rate how good or bad a given output is. The reward model was then used to fine tune GPT-3. A token is about 0.75 words.
Hey Dan, thanks for the post! You mentioned that byte pair encoding is used for efficiency - but this is something that confuses me a bit. If it were possible to use character level encoding for an LLM, wouldn't someone have done it by now? Or maybe they have and I just haven't come across it. But when I was learning how transformers work, it seemed like the dimension of the embedding space would effectively be limited by the size of the token vocabulary. Using an embedding space with more dimensions than the number of unique tokens would just end up making all the token representations orthogonal to each other (I think). But an embedding space with 26 dimensions doesn't seem likely to capture much useful world knowledge. Not to mention it would limit your context length because you could only have 26 sinusoids in your position encoding...
The date implies it is current (or this is a repost of an old article). I tested a few examples like: what dose the string “SolidGoldMagikarp” refer to? I got the correct answer.
or "can coughing effectiveness can stop a heart attack"
again I got the correct answer.